UniQueR: Unified Query-based Feedforward 3D Reconstruction
TL;DR
We propose an efficient pipeline that achieves 3D reconstruction based on sparse queries.

Abstract
We present UniQueR, a unified query-based feedforward framework for efficient and accurate 3D reconstruction from unconstrained images. Existing state-of-the-art feedforward models, such as Dust3R and VGGT, typically predict per-pixel point maps or depth maps—representations that remain fundamentally 2.5D and limited to visible surfaces. In contrast, UniQueR formulates reconstruction as a sparse 3D query inference problem.
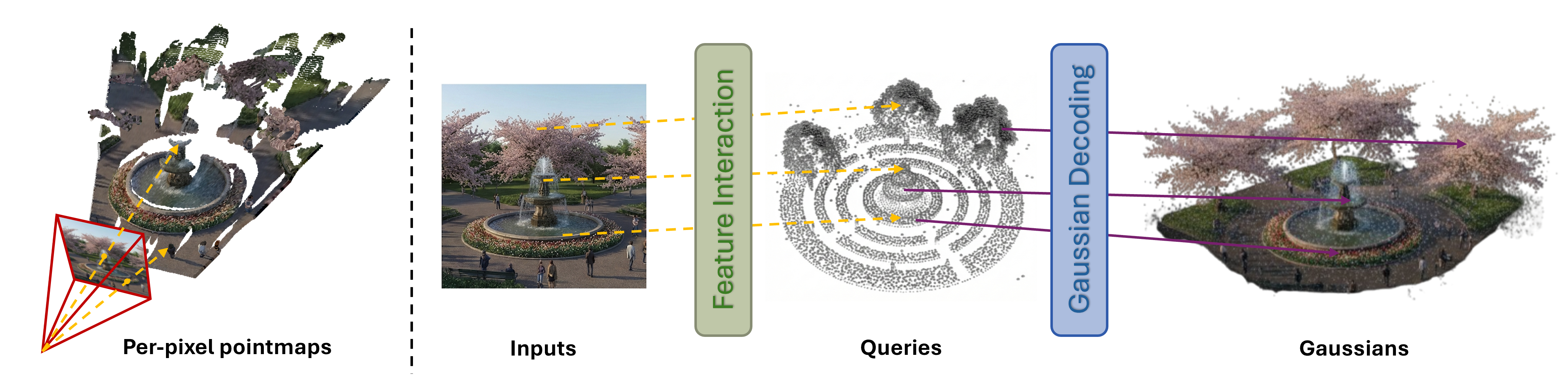
Figure 1: Illustration of pixel-aligned and query-based pipelines. Given input images, UniQueR predicts a sparse set of 3D queries that spawn Gaussians covering both observed surfaces and occluded regions in global space. Unlike pixel-aligned methods (e.g., AnySplat) that produce holes in unobserved areas, our query-based representation enables more complete 3D reconstruction with accurate geometry.
Our model learns a compact set of 3D anchor points that act as explicit geometric queries, enabling the network to infer full scene structure in a single forward pass without iterative optimization. Each query encodes spatial and semantic priors directly in 3D space, allowing UniQueR not only to recover surface geometry but also to reason about occluded and unseen regions. By leveraging unified query interactions across multi-view features, UniQueR achieves strong geometric expressiveness while substantially reducing memory and computational cost. Extensive experiments across multiple benchmarks show that UniQueR surpasses state-of-the-art feedforward reconstruction approaches in both accuracy and efficiency, delivering high-fidelity 3D reconstructions with an order of magnitude fewer queries than dense alternatives.
Methodology
The core of our pipeline consists of an image transformer and a query transformer. Given unposed input images, a framewise ViT encoder and cross-view transformer extract multi-view features used to predict pointmaps, depth, and camera poses. A sparse set of learnable 3D queries interacts with these image tokens through the Query Transformer, then spawns 3D Gaussians that are rendered via a differentiable Gaussian splatting module.
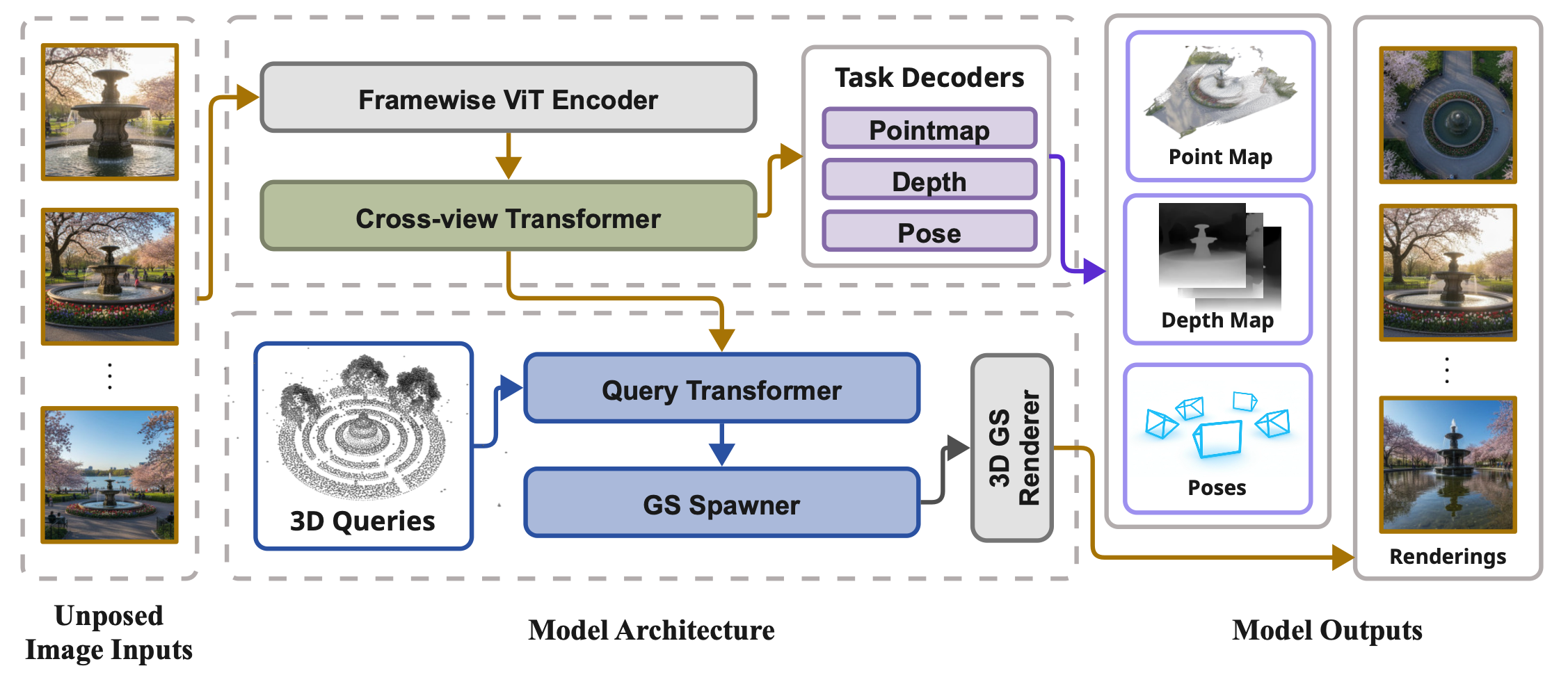
Figure 2: Overview. Given unposed input images, a framewise ViT encoder and cross-view transformer extract multi-view features used to predict pointmaps, depth, and camera poses. A sparse set of learnable 3D queries interacts with these image tokens through the Query Transformer, then spawns 3D Gaussians that are rendered via a differentiable Gaussian splatting module.
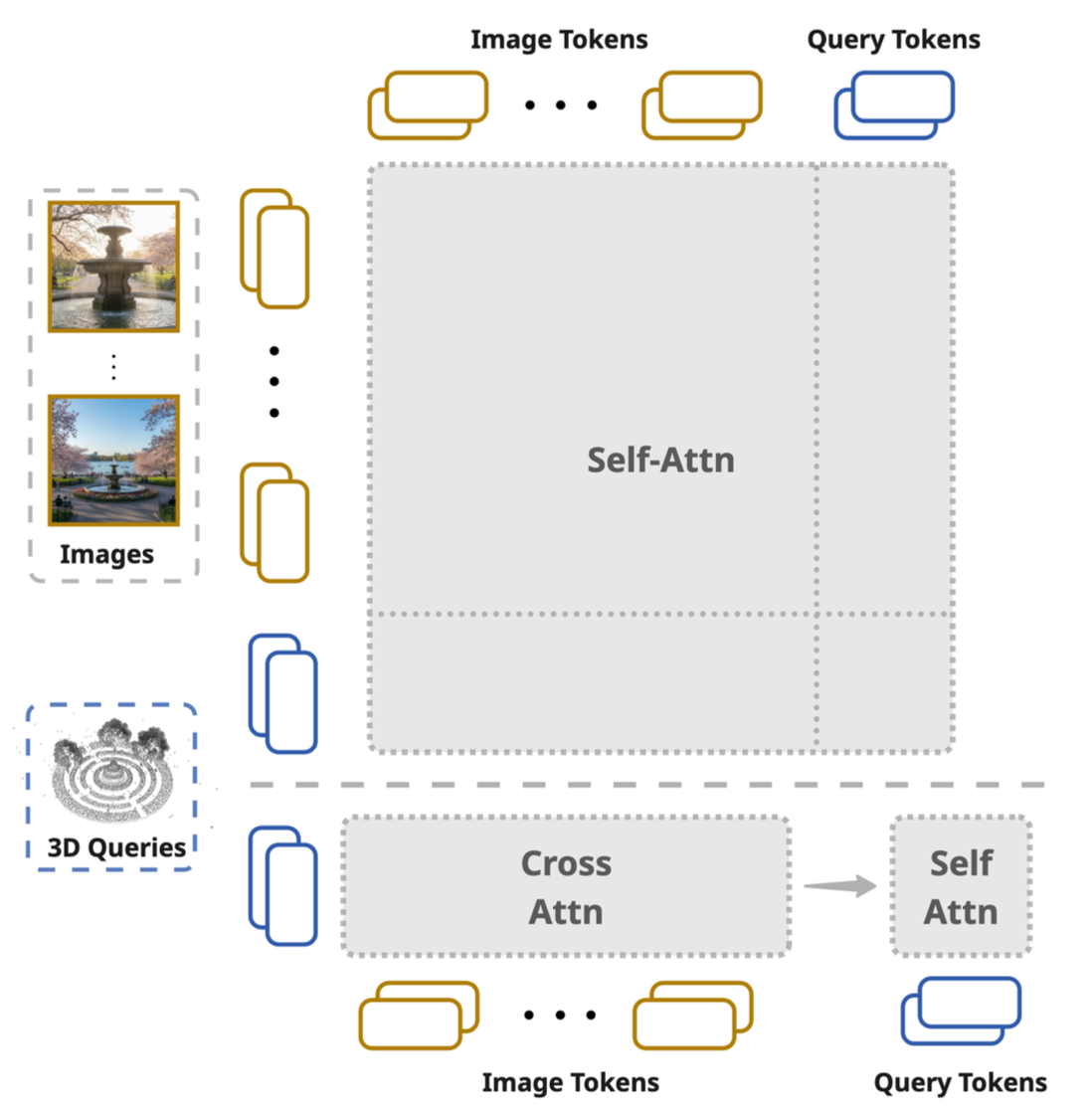
Decoupled Query Attention
We adopt a decoupled attention design. Instead of full self-attention over all tokens, we first apply cross-attention from queries to image tokens, allowing queries to absorb image-derived information, followed by self-attention among the queries themselves.
This reduces the computational complexity to $\mathcal{O}\left(QNHW/p^2+Q^2\right)$, yielding substantial memory savings and enabling the model to scale up to larger size, high-resolution images and more queries.
Results
Qualitative Comparison
We evaluate our method on standard benchmarks. Below we show visual comparisons against NopoSplat and Gaussian Splatting baselines alongside the Ground Truth (GT).
Video Comparison
We additionally compare AnySplat and UniQueR on one showcased scene. Use the selector below to switch between rendered RGB and depth videos.
Quantitative Metrics
We report PSNR, SSIM, LPIPS, and runtime on the Mip-NeRF benchmark. Use the toggle below to compare the 3-view and 6-view settings.
Citation
@misc{peng2026uniquer,
title={{UniQueR}: Unified Query-based Feedforward {3D} Reconstruction},
author={Peng, Chensheng and Herau, Quentin and Yang, Jiezhi and Xie, Yichen and Hu, Yihan and Zheng, Wenzhao and Strong, Matthew and Tomizuka, Masayoshi and Zhan, Wei},
year={2026},
eprint={},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/}
}